Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1129 results for "Bin-Tzong Chi" clear search
Livestock drought insurance model
Birgit Müller Felix John Jürgen Groeneveld Karin Frank Russell Toth | Published Tuesday, December 19, 2017 | Last modified Saturday, April 14, 2018The model analyzes the economic and ecological effects of a provision of livestock drought insurance for dryland pastoralists. More precisely, it yields qualitative insights into how long-term herd and pasture dynamics change through insurance.

Swidden farming by individual households
C Michael Barton | Published Sunday, April 27, 2008 | Last modified Saturday, April 27, 2013Swidden Farming is designed to explore the dynamics of agricultural land management strategies.

SearchResource
Romulus-Catalin Damaceanu | Published Friday, May 04, 2012 | Last modified Saturday, April 27, 2013An algorithm implemented in NetLogo that can be used for searching resources.
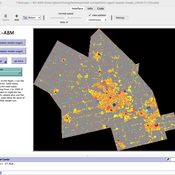
Retail Competition Agent-based Model
Derek Robinson Jiaxin Zhang | Published Sunday, January 03, 2021 | Last modified Wednesday, November 10, 2021The Retail Competition Agent-based Model (RC-ABM) is designed to simulate the retail competition system in the Region of Waterloo, Ontario, Canada, which which explicitly represents store competition behaviour. Through the RC-ABM, we aim to answer 4 research questions: 1) What is the level of correspondence between market share and revenue acquisition for an agent-based approach compared to a traditional location-allocation-based approach? 2) To what degree can the observed store spatial pattern be reproduced by competition? 3) To what degree are their path dependent patterns of retail success? 4) What is the relationship between retail survival and the endogenous geographic characteristics of stores and consumer expenditures?

Simulating Components of the Reinforcing Spirals Model and Spiral of Silence
František Kalvas Michael D. Slater Ashley Sanders-Jackson | Published Friday, November 05, 2021Communication processes occur in complex dynamic systems impacted by person attitudes and beliefs, environmental affordances, interpersonal interactions and other variables that all change over time. Many of the current approaches utilized by Communication researchers are unable to consider the full complexity of communication systems or the over time nature of our data. We apply agent-based modeling to the Reinforcing Spirals Model and the Spiral of Silence to better elucidate the complex and dynamic nature of this process. Our preliminary results illustrate how environmental affordances (i.e. social media), closeness of the system and probability of outspokenness may impact how attitudes change over time. Additional analyses are also proposed.
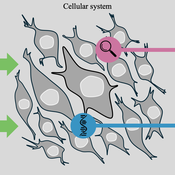
GenoScope
Kristin Crouse | Published Wednesday, May 29, 2024 | Last modified Wednesday, April 09, 2025GenoScope is a modular agent-based model designed to simulate how cells respond to environmental stressors or other treatment conditions across species. Genes, treatment conditions, and cell physiology outcomes are represented as interacting agents that influence each other’s behavior over time. Rather than imposing fixed interaction rules, GenoScope initializes with randomized regulatory logic and calibrates rule sets based on empirical data. Calibration is grounded in a common-garden experiment involving 16 mammalian species—including humans, dolphins, bats, and camels—exposed to varying levels of temperature, glucose, and oxygen. This comparative approach enables the identification of mechanisms by which animal cells achieve robustness under extreme environmental conditions.

Peer reviewed WaDemEsT-Water Demand Estimation Tool for Residential Areas
Kamil Aybuğa | Published Tuesday, February 18, 2025This model simulates household water consumption patterns in an urban environment. Its current setup compares monthly water consumption data, and the results of a daily heuristic water demand model with the simulation results produced by household demographics that is fine tuned via some base demand model. It’s designed to estimate and analyze water demand based on various factors including household demographics, daily routines of residents (working, weekending, vacation patterns), weather conditions (temperature and precipitation), appliance usage patterns, seasonal variations, and special periods such as weekends and holidays. The model aims to help understand how different factors influence residential water consumption and can be used for water demand forecasting and management.
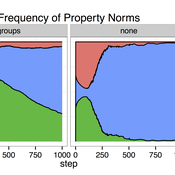
Cultural Group Selection of Sustainable Institutions
Timothy Waring Paul Smaldino Sandra H Goff | Published Wednesday, June 10, 2015 | Last modified Tuesday, August 04, 2015We develop a spatial, evolutionary model of the endogenous formation and dissolution of groups using a renewable common pool resource. We use this foundation to measure the evolutionary pressures at different organizational levels.
RecovUS: An Agent-Based Model of Post-Disaster Household Recovery
Saeed Moradi | Published Thursday, July 30, 2020The purpose of this model is to explain the post-disaster recovery of households residing in their own single-family homes and to predict households’ recovery decisions from drivers of recovery. Herein, a household’s recovery decision is repair/reconstruction of its damaged house to the pre-disaster condition, waiting without repair/reconstruction, or selling the house (and relocating). Recovery drivers include financial conditions and functionality of the community that is most important to a household. Financial conditions are evaluated by two categories of variables: costs and resources. Costs include repair/reconstruction costs and rent of another property when the primary house is uninhabitable. Resources comprise the money required to cover the costs of repair/reconstruction and to pay the rent (if required). The repair/reconstruction resources include settlement from the National Flood Insurance (NFI), Housing Assistance provided by the Federal Emergency Management Agency (FEMA-HA), disaster loan offered by the Small Business Administration (SBA loan), a share of household liquid assets, and Community Development Block Grant Disaster Recovery (CDBG-DR) fund provided by the Department of Housing and Urban Development (HUD). Further, household income determines the amount of rent that it can afford. Community conditions are assessed for each household based on the restoration of specific anchors. ASNA indexes (Nejat, Moradi, & Ghosh 2019) are used to identify the category of community anchors that is important to a recovery decision of each household. Accordingly, households are indexed into three classes for each of which recovery of infrastructure, neighbors, or community assets matters most. Further, among similar anchors, those anchors are important to a household that are located in its perceived neighborhood area (Moradi, Nejat, Hu, & Ghosh 2020).
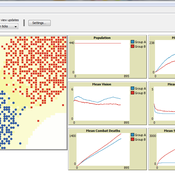
This model was developed to test the usability of evolutionary computing and reinforcement learning by extending a well known agent-based model. Sugarscape (Epstein & Axtell, 1996) has been used to demonstrate migration, trade, wealth inequality, disease processes, sex, culture, and conflict. It is on conflict that this model is focused to demonstrate how machine learning methodologies could be applied.
The code is based on the Sugarscape 2 Constant Growback model, availble in the NetLogo models library. New code was added into the existing model while removing code that was not needed and modifying existing code to support the changes. Support for the original movement rule was retained while evolutionary computing, Q-Learning, and SARSA Learning were added.
Displaying 10 of 1129 results for "Bin-Tzong Chi" clear search