Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 191 results for "Ingo Kowarik" clear search
Food Safety Inspection Model - Stores Signal with Errors
Sara Mcphee-Knowles | Published Wednesday, March 05, 2014 | Last modified Monday, April 08, 2019The Inspection Model represents a basic food safety system where inspectors, consumers and stores interact. The purpose of the model is to provide insight into an optimal level of inspectors in a food system by comparing three search strategies.
Food Safety Inspection Model - Stores Signal
Sara Mcphee-Knowles | Published Wednesday, March 05, 2014 | Last modified Monday, August 26, 2019The Inspection Model represents a basic food safety system where inspectors, consumers and stores interact. The purpose of the model is to provide insight into an optimal level of inspectors in a food system by comparing three search strategies.
Peer reviewed Simulating the Economic Impact of Boko Haram on a Cameroonian Floodplain
Mark Moritz Nathaniel Henry Sarah Laborde | Published Saturday, October 22, 2016 | Last modified Wednesday, June 07, 2017This model examines the potential impact of market collapse on the economy and demography of fishing households in the Logone Floodplain, Cameroon.

Agent-Based Simulation for International Tax Compliance
Peter Gerbrands | Published Tuesday, July 18, 2023Country-by-Country Reporting and Automatic Exchange of Information have recently been implemented in European Union (EU) countries. These international tax reforms increase tax compliance in the short term. In the long run, however, taxpayers will continue looking abroad to avoid taxation and, countries, looking for additional revenues, will provide opportunities. As a result, tax competition intensifies and the initial increase in compliance could reverse. To avoid international tax reforms being counteracted by tax competition, this paper suggests bilateral responsive regulation to maximize compliance. This implies that countries would use different tax policy instruments toward other countries, including tax and secrecy havens.
To assess the effectiveness of fully or partially enforce tax policies, this agent based model has been ran many times under different enforcement rules, which influence the perceived enforced- and voluntary compliance, as the slippery-slope model prescribes. Based on the dynamics of this perception and the extent to which agents influence each other, the annual amounts of tax evasion, tax avoidance and taxes paid are calculated over longer periods of time.
The agent-based simulation finds that a differentiated policy response could increase tax compliance by 6.54 percent, which translates into an annual increase of €105 billion in EU tax revenues on income, profits, and capital gains. Corporate income tax revenues in France, Spain, and the UK alone would already account for €35 billion.
Agent-based tax evasion model for investigating impacts of public disclosure
Hiroyuki Sano | Published Thursday, March 14, 2024The model explores the impact of public disclosure on tax compliance among diverse agents, including individual taxpayers and a tax authority. It incorporates heterogeneous preferences and income endowments among taxpayers, captured through a utility function that considers psychic costs subtracted from expected pecuniary utility. These costs include moral, reciprocity, and stigma costs associated with norm violations, leading to variations in taxpayers’ risk attitudes and related parameters. The tax authority’s attributes, such as the frequency of random audits, penalty rate, and the choice between partial or full disclosure, remain fixed throughout the simulation. Income endowments and preference parameters are randomly assigned to taxpayers at the outset.
Taxpayers maximize their expected utility by reporting income, taking into account tax, penalty, and audit rates. They make annual decisions based on their own and their peers’ behaviors from the previous year. Taxpayers indirectly interact at the societal level through public disclosure conducted by the tax authority, exchanging tax information among peers. Each period in the simulation collects data on total reported income, average compliance rates per income group, distribution of compliance rates, counts of compliers, full evaders, partial evaders, and the numbers of taxpayers experiencing guilt and anger. The model evaluates whether public disclosure positively or negatively impacts compliance rates and quantifies this impact based on aggregated individual reporting behaviors.

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…

MASTOC-LLM (Multi-Agent System Tragedy of the Commons - Large Language Models)
Thomas Tuoti | Published Monday, May 18, 2026 | Last modified Tuesday, May 19, 2026MASTOC-LLM extends the classic Multi-Agent System Tragedy of the Commons (MASTOC) model by replacing hard-coded behavioral rules with autonomous decision-making powered by large language models (LLMs). Three heterogeneous agents manage herds of cows on a shared grassland commons. Each tick, an agent receives a structured prompt describing current resource levels, its own herd size, peer behavior, and — optionally — a rolling memory of recent rounds and messages from neighboring agents. The LLM returns a stocking decision (add, remove, or hold cows) together with a natural-language rationale and, when communication is enabled, a short message to broadcast to peers.
The model is designed to test whether LLM agents spontaneously develop Ostrom-style common-pool resource governance (mutual monitoring, graduated sanctions, graduated rule revision) or instead fall into identifiable failure modes. Preliminary experiments with Claude Haiku 4.5, GPT-5.4-mini, and DeepSeek R1:32b have revealed four recurring collapse patterns — Cooperative Paralysis, Defection Cascade, Overshoot-Panic, and Hybrid Architecture Failure — whose onset timing is sensitive to memory length, inter-agent communication, and the post-training alignment approach of the underlying model.
MASTOC-LLM is intended as a laboratory for generative agent-based modelling (GABM) methodology: it provides a clean, well-understood commons baseline against which LLM behavioral hypotheses can be systematically tested and compared across models, parameter sweeps, and alignment regimes.
ABMIND: An Empirically Informed Agent-Based Model of Psychological Distance and Environmental Protection Behavior
Wenhan Feng | Published Saturday, June 13, 2026ABMIND, the Agent-Based Model of Individual Psychological Distance, is a modeling framework developed to examine how psychological distance influences environmental protection behavior in coastal farming communities in southern China. Using household survey data and empirically estimated behavioral pathways, the model represents how uncertainty shapes four dimensions of psychological distance, namely temporal, spatial, social and hypothetical distance, and how these dimensions guide protection and degradation decisions. Agents include households, government actors and mangrove ecosystem patches, connected through social networks and ecological feedbacks that affect learning, expectations and perceived benefits. Policy interventions such as rewards, penalties and publicity guidance efforts work by modifying uncertainty and psychological distance rather than directly controlling behavior. ABMIND is implemented as a spatially explicit model following the ODD protocol, and a concise user guide is provided. In developing ABMIND we introduce a structured validation workflow that links statistical mediation analysis with simulation-based diagnostics, allowing empirical cognitive mechanisms to be systematically embedded and tested within the ABM. This integrated approach strengthens the credibility of psychological-mechanism models and supports their use in policy evaluation. The framework offers a methodological platform for integrating cognitive mechanisms into agent-based environmental behavior modeling and for evaluating policy strategies that support ecosystem protection.
Model paper:
ABMIND: An empirically informed agent-based model of psychological distance and environmental protection behaviour
Ecological Modelling
https://doi.org/10.1016/j.ecolmodel.2026.111700
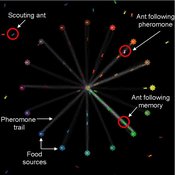
Composite Collective Decision Making - ant colony foraging model
Tomer Czaczkes Benjamin I Czaczkes | Published Thursday, December 17, 2015The model explores how two types of information - social (in the form of pheromone trails) and private (in the form of route memories) affect ant colony level foraging in a variable enviroment.
Informal risk-sharing cooperatives : ORP and Learning
Juliette Rouchier Victorien Barbet Renaud Bourlès | Published Monday, February 13, 2017 | Last modified Tuesday, May 16, 2023The model studies the dynamics of risk-sharing cooperatives among heterogeneous farmers. Based on their knowledge on their risk exposure and the performance of the cooperative farmers choose whether or not to remain in the risk-sharing agreement.
Displaying 10 of 191 results for "Ingo Kowarik" clear search