Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 64 results for "Merlin Radbruch" clear search
An Agent-Based Model of Insurance Customer Behaviour with Word of Mouth Network in C#
Rei England Iqbal Owadally Douglas Wright | Published Friday, March 04, 2022This is an agent-based model with two types of agents: customers and insurers. Insurers are price-takers who choose how much to spend on their service quality, and customers evaluate insurers based on premium, brand preference, and their perceived service quality. Customers are also connected in a small-world network and may share their opinions with their network.
The ABM contains two types of agents: insurers and customers. These act within the environment of a motor insurance market. At each simulation, the model undergoes the following steps:
- Network generation: At the start of the simulation, the model generates a small world network of social links between the customers, and randomly assigns each customer to an initial insurer ...
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
Viability analysis of a population submitted to floods
Sophie Martin | Published Wednesday, September 22, 2021This model computes the guaranteed viability kernel of a model describing the evolution of a population submitted to successive floods.
The population is described by its wealth and its adaptation rate to floods, the control are information campaigns that have a cost but increase the adaptation rate and the expected successive floods belong to given set defined by the maximal high and the minimal time between two floods.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
Artificial Long House Valley-Black Mesa
Lisa Sattenspiel Amy Warren | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Hegmon's Model of Sharing
Sean Bergin | Published Thursday, May 02, 2013The purpose of Hegmon’s Sharing model is to develop an understanding of the effect sharing strategies have on household survival.
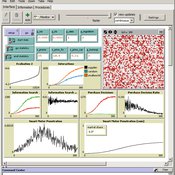
A consumer-demand simulation for Smart Metering tariffs (Innovation Diffusion)
Martin Rixin | Published Thursday, August 18, 2011 | Last modified Saturday, April 27, 2013An Agent-based model simulates consumer demand for Smart Metering tariffs. It utilizes the Bass Diffusion Model and Rogers´s adopter categories. Integration of empirical census microdata enables a validated socio-economic background for each consumer.
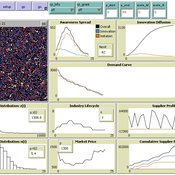
(Policy induced) Diffusion of Innovations - An integrated demand-supply Model based on Cournot Competition
Martin Rixin | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013Objective is to simulate policy interventions in an integrated demand-supply model. The underlying demand function links both sides. Diffusion proceeds if interactions distribute awareness (Epidemic effect) and rivalry reduces the market price (Probit effect). Endogeneity is given due to the fact that consumer awareness as well as their willingness-to-pay drives supply-side rivalry. Firm´s entry and exit decisions as well as quantity and price settings are driven by Cournot competition.
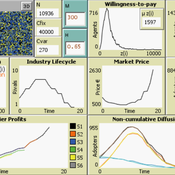
9 Maturity levels in Empirical Validation - An innovation diffusion example
Martin Rixin | Published Wednesday, October 19, 2011 | Last modified Saturday, April 27, 2013Several taxonomies for empirical validation have been published. Our model integrates different methods to calibrate an innovation diffusion model, ranging from simple randomized input validation to complex calibration with the use of microdata.
Peer reviewed Torsten Hägerstrand’s Spatial Innovation Diffusion Model
Sean Bergin | Published Friday, September 14, 2012 | Last modified Saturday, April 27, 2013This model is a replication of Torsten Hägerstrand’s 1965 model–one of the earliest known calibrated and validated simulations with implicit “agent based” methodology.
Displaying 10 of 64 results for "Merlin Radbruch" clear search