Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 268 results for "David Moore" clear search
Location Analysis Hybrid ABM
Lukasz Kowalski | Published Friday, February 08, 2019The purpose of this hybrid ABM is to answer the question: where is the best place for a new swimming pool in a region of Krakow (in Poland)?
The model is well described in ODD protocol, that can be found in the end of my article published in JASSS journal (available online: http://jasss.soc.surrey.ac.uk/22/1/1.html ). Comparison of this kind of models with spatial interaction ones, is presented in the article. Before developing the model for different purposes, area of interest or services, I recommend reading ODD protocol and the article.
I published two films on YouTube that present the model: https://www.youtube.com/watch?v=iFWG2Xv20Ss , https://www.youtube.com/watch?v=tDTtcscyTdI&t=1s
…
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
A Simple Agent Based Modeling Tool for Plastic and Debris Tracking in Oceans
Subu Kandaswamy Koushik Sura Bhaskar Sai Amulya Murukutla Sai Pranay Raju Chinthala Abhishek Bobbillapati | Published Monday, October 04, 2021Plastics and the pollution caused by their waste have always been a menace to both nature and humans. With the continual increase in plastic waste, the contamination due to plastic has stretched to the oceans. Many plastics are being drained into the oceans and rose to accumulate in the oceans. These plastics have seemed to form large patches of debris that keep floating in the oceans over the years. Identification of the plastic debris in the ocean is challenging and it is essential to clean plastic debris from the ocean. We propose a simple tool built using the agent-based modeling framework NetLogo. The tool uses ocean currents data and plastic data both being loaded using GIS (Geographic Information System) to simulate and visualize the movement of floatable plastic and debris in the oceans. The tool can be used to identify the plastic debris that has been piled up in the oceans. The tool can also be used as a teaching aid in classrooms to bring awareness about the impact of plastic pollution. This tool could additionally assist people to realize how a small plastic chunk discarded can end up as large debris drifting in the oceans. The same tool might help us narrow down the search area while looking out for missing cargo and wreckage parts of ships or flights. Though the tool does not pinpoint the location, it might help in reducing the search area and might be a rudimentary alternative for more computationally expensive models.

Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
A Data-Driven Approach of Layout Evaluation for Electric Vehicle Charging Infrastructure Using Agent-Based Simulation and GIS
yue zhang | Published Thursday, September 21, 2023The development and popularisation of new energy vehicles have become a global consensus. The shortage and unreasonable layout of electric vehicle charging infrastructure (EVCI) have severely restricted the development of electric vehicles. In the literature, many methods can be used to optimise the layout of charging stations (CSs) for producing good layout designs. However, more realistic evaluation and validation should be used to assess and validate these layout options. This study suggested an agent-based simulation (ABS) model to evaluate the layout designs of EVCI and simulate the driving and charging behaviours of electric taxis (ETs). In the case study of Shenzhen, China, GPS trajectory data were used to extract the temporal and spatial patterns of ETs, which were then used to calibrate and validate the actions of ETs in the simulation. The ABS model was developed in a GIS context of an urban road network with travelling speeds of 24 h to account for the effects of traffic conditions. After the high-resolution simulation, evaluation results of the performance of EVCI and the behaviours of ETs can be provided in detail and in summary. Sensitivity analysis demonstrates the accuracy of simulation implementation and aids in understanding the effect of model parameters on system performance. Maximising the time satisfaction of ET users and reducing the workload variance of EVCI were the two goals of a multiobjective layout optimisation technique based on the Pareto frontier. The location plans for the new CS based on Pareto analysis can significantly enhance both metrics through simulation evaluation.
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.
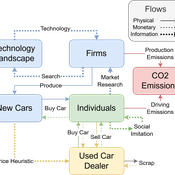
Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…

The role of spatial foresight in models of hominin dispersal
Colin Wren | Published Monday, February 24, 2014 | Last modified Monday, July 14, 2014The natural selection of foresight, an accuracy at assess the environment, under degrees of environmental heterogeneity. The model is designed to connect local scale mobility, from foraging, with the global scale phenomenon of population dispersal.
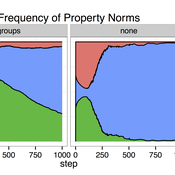
Cultural Group Selection of Sustainable Institutions
Timothy Waring Paul Smaldino Sandra H Goff | Published Wednesday, June 10, 2015 | Last modified Tuesday, August 04, 2015We develop a spatial, evolutionary model of the endogenous formation and dissolution of groups using a renewable common pool resource. We use this foundation to measure the evolutionary pressures at different organizational levels.

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
Displaying 10 of 268 results for "David Moore" clear search