Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1012 results for "Chantal van Esch" clear search
Models for assessing empowerment through public policies in rural areas in Brazil
Marcos Aurélio Santos da Silva | Published Monday, April 08, 2019Brazil has initiated two territorial public policies for a rural sustainable development, the National Program for Sustainable Development of the Rural Territories (PRONAT) and Citizenship Territory Program (PTC). These public policies aims, as a condition for its effectiveness, the equilibrium of the power relations between actors which participate in the Collegiate for Territorial Development (CODETER) of each Rural Territory. Our research studies the hypotheses that, in the Rural Territories submitted to the PRONAT and PTC public policies, the power and reciprocity relations between actors engaged in the CODETER effectively have evolved in favor of the civil society representatives to the detriment of the public powers, notably the mayors.
The SocLab approach has been applied in two case studies and four models representing the Southern Rural Territory of Sergipe (TRSS) and the São Francisco Rural Territory (TRBSF) were designed for two referential periods, 2008-2012 and 2013-2017. These models were developed to evaluate the empowerment of the civil society in these rural territories due to thes two public policies, PRONAT and PTC.
CINCH1 (Covid-19 INfection Control in Hospitals)
Nick Gotts | Published Sunday, August 29, 2021CINCH1 (Covid-19 INfection Control in Hospitals), is a prototype model of physical distancing for infection control among staff in University College London Hospital during the Covid-19 pandemic, developed at the University of Leeds, School of Geography. It models the movement of collections of agents in simple spaces under conflicting motivations of reaching their destination, maintaining physical distance from each other, and walking together with a companion. The model incorporates aspects of the Capability, Opportunity and Motivation of Behaviour (COM-B) Behaviour Change Framework developed at University College London Centre for Behaviour Change, and is aimed at informing decisions about behavioural interventions in hospital and other workplace settings during this and possible future outbreaks of highly contagious diseases. CINCH1 was developed as part of the SAFER (SARS-CoV-2 Acquisition in Frontline Health Care Workers – Evaluation to Inform Response) project
(https://www.ucl.ac.uk/behaviour-change/research/safer-sars-cov-2-acquisition-frontline-health-care-workers-evaluation-inform-response), funded by the UK Medical Research Council. It is written in Python 3.8, and built upon Mesa version 0.8.7 (copyright 2020 Project Mesa Team).
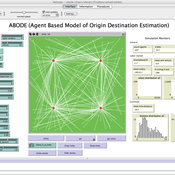
ABODE - Agent Based Model of Origin Destination Estimation
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The agent based model matches origins and destinations using employment search methods at the individual level.

A stylized scale model to codesign with villagers an agent-based model of bushmeat hunting in the periphery of Korup National Park (Cameroon)

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
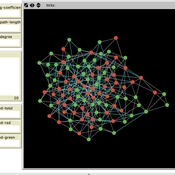
Homophily-driven Network Evolution and Diffusion
Gönenç Yücel Mustafa Yavaş | Published Thursday, January 08, 2015The model is an experimental ground to study the impact of network structure on diffusion. It allows to construct a social network that already has some measurable level of homophily, and simulate a diffusion process over this social network.
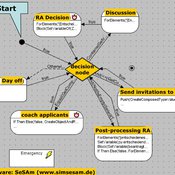
NarrABS
Tilman Schenk | Published Thursday, September 20, 2012 | Last modified Saturday, April 27, 2013An agent based simulation of a political process based on stakeholder narratives
Peer reviewed Torsten Hägerstrand’s Spatial Innovation Diffusion Model
Sean Bergin | Published Friday, September 14, 2012 | Last modified Saturday, April 27, 2013This model is a replication of Torsten Hägerstrand’s 1965 model–one of the earliest known calibrated and validated simulations with implicit “agent based” methodology.
The Evolution of Multiple Resistant Strains: An Abstract Model of Systemic Treatment and Accumulated Resistance
Benjamin Nye | Published Wednesday, August 31, 2011 | Last modified Saturday, April 27, 2013This model is intended to explore the effectiveness of different courses of interventions on an abstract population of infections. Illustrative findings highlight the importance of the mechanisms for variability and mutation on the effectiveness of different interventions.
How do bots influence beliefs on social media? Why do beliefs propagated by social bots spread far and wide, yet does their direct influence appear to be limited?
This model extends Axelrod’s model for the dissemination of culture (1997), with a social bot agent–an agent who only sends information and cannot be influenced themselves. The basic network is a ring network with N agents connected to k nearest neighbors. The agents have a cultural profile with F features and Q traits per feature. When two agents interact, the sending agent sends the trait of a randomly chosen feature to the receiving agent, who adopts this trait with a probability equal to their similarity. To this network, we add a bot agents who is given a unique trait on the first feature and is connected to a proportion of the agents in the model equal to ‘bot-connectedness’. At each timestep, the bot is chosen to spread one of its traits to its neighbors with a probility equal to ‘bot-activity’.
The main finding in this model is that, generally, bot activity and bot connectedness are both negatively related to the success of the bot in spreading its unique message, in equilibrium. The mechanism is that very active and well connected bots quickly influence their direct contacts, who then grow too dissimilar from the bot’s indirect contacts to quickly, preventing indirect influence. A less active and less connected bot leaves more space for indirect influence to occur, and is therefore more successful in the long run.
Displaying 10 of 1012 results for "Chantal van Esch" clear search