Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 994 results for "Dave van Wees" clear search
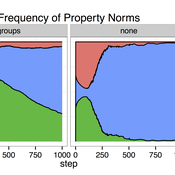
Cultural Group Selection of Sustainable Institutions
Timothy Waring Paul Smaldino Sandra H Goff | Published Wednesday, June 10, 2015 | Last modified Tuesday, August 04, 2015We develop a spatial, evolutionary model of the endogenous formation and dissolution of groups using a renewable common pool resource. We use this foundation to measure the evolutionary pressures at different organizational levels.

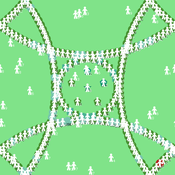
Model of communication between two groups of managers in the course of project implementation
Smarzhevskiy Ivan | Published Monday, December 07, 2020This is a simulation model of communication between two groups of managers in the course of project implementation. The “world” of the model is a space of interaction between project participants, each of which belongs either to a group of work performers or to a group of customers. Information about the progress of the project is publicly available and represents the deviation Earned value (EV) from the planned project value (cost baseline).
The key elements of the model are 1) persons belonging to a group of customers or performers, 2) agents that are communication acts. The life cycle of persons is equal to the time of the simulation experiment, the life cycle of the communication act is 3 periods of model time (for the convenience of visualizing behavior during the experiment). The communication act occurs at a specific point in the model space, the coordinates of which are realized as random variables. During the experiment, persons randomly move in the model space. The communication act involves persons belonging to a group of customers and a group of performers, remote from the place of the communication act at a distance not exceeding the value of the communication radius (MaxCommRadius), while at least one representative from each of the groups must participate in the communication act. If none are found, the communication act is not carried out. The number of potential communication acts per unit of model time is a parameter of the model (CommPerTick).
The managerial sense of the feedback is the stimulating effect of the positive value of the accumulated communication complexity (positive background of the project implementation) on the productivity of the performers. Provided there is favorable communication (“trust”, “mutual understanding”) between the customer and the contractor, it is more likely that project operations will be performed with less lag behind the plan or ahead of it.
The behavior of agents in the world of the model (change of coordinates, visualization of agents’ belonging to a specific communicative act at a given time, etc.) is not informative. Content data are obtained in the form of time series of accumulated communicative complexity, the deviation of the earned value from the planned value, average indicators characterizing communication - the total number of communicative acts and the average number of their participants, etc. These data are displayed on graphs during the simulation experiment.
The control elements of the model allow seven independent values to be varied, which, even with a minimum number of varied values (three: minimum, maximum, optimum), gives 3^7 = 2187 different variants of initial conditions. In this case, the statistical processing of the results requires repeated calculation of the model indicators for each grid node. Thus, the set of varied parameters and the range of their variation is determined by the logic of a particular study and represents a significant narrowing of the full set of initial conditions for which the model allows simulation experiments.
…
Peer reviewed Personnel decisions in the hierarchy
Smarzhevskiy Ivan | Published Friday, August 19, 2022This is a model of organizational behavior in the hierarchy in which personnel decisions are made.
The idea of the model is that the hierarchy, busy with operations, is described by such characteristics as structure (number and interrelation of positions) and material, filling these positions (persons with their individual performance). A particular hierarchy is under certain external pressure (performance level requirement) and is characterized by the internal state of the material (the distribution of the perceptions of others over the ensemble of persons).
The World of the model is a four-level hierarchical structure, consisting of shuff positions of the top manager (zero level of the hierarchy), first-level managers who are subordinate to the top manager, second-level managers (subordinate to the first-level managers) and positions of employees (the third level of the hierarchy). ) subordinated to the second-level managers. Such a hierarchy is a tree, i.e. each position, with the exception of the position of top manager, has a single boss.
Agents in the model are persons occupying the specified positions, the number of persons is set by the slider (HumansQty). Personas have some operational performance (harisma, an unfortunate attribute name left over from the first edition of the model)) and a sense of other personas’ own perceptions. Performance values are distributed over the ensemble of persons according to the normal law with some mean value and variance.
The value of perception by agents of each other is positive or negative (implemented in the model as numerical values equal to +1 and -1). The distribution of perceptions over an ensemble of persons is implemented as a random variable specified by the probability of negative perception, the value of which is set by the control elements of the model interface. The numerical value of the probability equal to 0 corresponds to the case in which all persons positively perceive each other (the numerical value of the random variable is equal to 1, which corresponds to the positive perception of the other person by the individual).
The hierarchy is occupied with operational activity, the degree of intensity of which is set by the external parameter Difficulty. The level of productivity of each manager OAIndex is equal to the level of productivity of the department he leads and is the ratio of the sum of productivity of employees subordinate to the head to the level of complexity of the work Difficulty. An increase in the numerical value of Difficulty leads to a decrease in the OAIndex for all subdivisions of the hierarchy. The managerial meaning of the OAIndex indicator is the percentage of completion of the load specified for the hierarchy as a whole, i.e. the ratio of the actual performance of the structural subdivisions of the hierarchy to the required performance, the level of which is specified by the value of the Difficulty parameter.
…
GODS: Gossip-Oriented Dilemma Simulator
Jan Majewski | Published Wednesday, September 04, 2024 | Last modified Monday, September 29, 2025Model of influence of access to social information spread via social network on decisions in a two-person game.
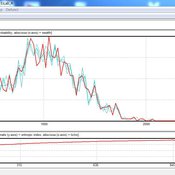
06 EiLab V1.40 – Entropic Index Laboratory
Garvin Boyle | Published Monday, March 19, 2018There is a new type of economic model called a capital exchange model, in which the biophysical economy is abstracted away, and the interaction of units of money is studied. Benatti, Drăgulescu and Yakovenko described at least eight capital exchange models – now referred to collectively as the BDY models – which are replicated as models A through H in EiLab. In recent writings, Yakovenko goes on to show that the entropy of these monetarily isolated systems rises to a maximal possible value as the model approaches steady state, and remains there, in analogy of the 2nd law of thermodynamics. EiLab demonstrates this behaviour. However, it must be noted that we are NOT talking about thermodynamic entropy. Heat is not being modeled – only simple exchanges of cash. But the same statistical formulae apply.
In three unpublished papers and a collection of diary notes and conference presentations (all available with this model), the concept of “entropic index” is defined for use in agent-based models (ABMs), with a particular interest in sustainable economics. Models I and J of EiLab are variations of the BDY model especially designed to study the Maximum Entropy Principle (MEP – model I) and the Maximum Entropy Production Principle (MEPP – model J) in ABMs. Both the MEPP and H.T. Odum’s Maximum Power Principle (MPP) have been proposed as organizing principles for complex adaptive systems. The MEPP and the MPP are two sides of the same coin, and an understanding of their implications is key, I believe, to understanding economic sustainability. Both of these proposed (and not widely accepted) principles describe the role of entropy in non-isolated systems in which complexity is generated and flourishes, such as ecosystems, and economies.
EiLab is one of several models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, and CmLab.
Competitive Arousal Agent Based Model
Zoé Chollet | Published Friday, May 13, 2022What is it?
This model demonstrates a very simple bidding market where buyers try to acquire a desired item at the best price in a competitive environment
…

Peer reviewed The Garbage Can Model of Organizational Choice
Guido Fioretti | Published Monday, April 20, 2020 | Last modified Thursday, April 23, 2026The Garbage Can Model of Organizational Choice is a fundamental model of organizational decision-making originally proposed by J.D. Cohen, J.G. March and J.P. Olsen in 1972. In the 2000s, G. Fioretti and A. Lomi presented a NetLogo agent-based interpretation of this model. This code is the NetLogo 6.1.1 updated version of the Fioretti-Lomi model.
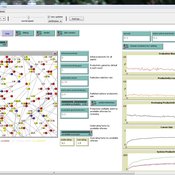
Peer Review Model
Flaminio Squazzoni Claudio Gandelli | Published Wednesday, September 05, 2012 | Last modified Saturday, April 27, 2013This model looks at implications of author/referee interaction for quality and efficiency of peer review. It allows to investigate the importance of various reciprocity motives to ensure cooperation. Peer review is modelled as a process based on knowledge asymmetries and subject to evaluation bias. The model includes various simulation scenarios to test different interaction conditions and author and referee behaviour and various indexes that measure quality and efficiency of evaluation […]
MERCURY extension: population
Tom Brughmans | Published Thursday, May 23, 2019This model is an extended version of the original MERCURY model (https://www.comses.net/codebases/4347/releases/1.1.0/ ) . It allows for experiments to be performed in which empirically informed population sizes of sites are included, that allow for the scaling of the number of tableware traders with the population of settlements, and for hypothesised production centres of four tablewares to be used in experiments.
Experiments performed with this population extension and substantive interpretations derived from them are published in:
Hanson, J.W. & T. Brughmans. In press. Settlement scale and economic networks in the Roman Empire, in T. Brughmans & A.I. Wilson (ed.) Simulating Roman Economies. Theories, Methods and Computational Models. Oxford: Oxford University Press.
…
Cascades across networks are sufficient for the formation of echo chambers: An agent-based model
Jan-Philipp Fränken | Published Monday, January 11, 2021An agent-based model of echo chamber formation employing a Bayesian Source Credibility cognitive architecture limiting interactions to a single cascade.
Displaying 10 of 994 results for "Dave van Wees" clear search