Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1195 results for "Aad Kessler" clear search

Simulation of Self-enforcing Agreement in Cooperative Teams
Hang Xiong | Published Friday, April 01, 2016This is an agent-based model of the implementation of the self-enforcing agreement in cooperative teams.

Peer reviewed DogFoxCDVspillover
Aniruddha Belsare Matthew Gompper | Published Thursday, March 16, 2017 | Last modified Tuesday, April 04, 2017The purpose of this model is to better understand the dynamics of a multihost pathogen in two host system comprising of high densities of domestic hosts and sympatric wildlife hosts susceptible to the pathogen.
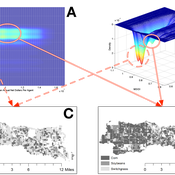
Stylized agricultural land-use model for resilience exploration
Patrick Bitterman | Published Tuesday, June 14, 2016 | Last modified Monday, April 08, 2019This model is a highly stylized land use model in the Clear Creek Watershed in Eastern Iowa, designed to illustrate the construction of stability landscapes within resilience theory.
Modeling a Victim-Centered Approach for Detection of Human Trafficking Victims within Migration Flows
Kyle Ballard Brant M Horio | Published Saturday, September 23, 2017The model employs an agent-based model for exploring the victim-centered approach to identifying human trafficking and the approach’s effectiveness in an abstract representation of migrant flows.

Replica of Turchin's (2003) Metaethnic Frontier model
Paul Smaldino | Published Sunday, February 15, 2026In his 2003 book, Historical Dynamics (ch. 4), Turchin describes and briefly analyzes a spatial ABM of his metaethnic frontier theory, which is essentially a formalization of a theory by Ibn Khaldun in the 14th century. In the model, polities compete with neighboring polities and can absorb them into an empire. Groups possess “asabiya”, a measure of social solidarity and a sense of shared purpose. Regions that share borders with other groups will have increased asabiya do to salient us vs. them competition. High asabiya enhances the ability to grow, work together, and hence wage war on neighboring groups and assimilate them into an empire. The larger the frontier, the higher the empire’s asabiya.
As an empire expands, (1) increased access to resources drives further growth; (2) internal conflict decreases asabiya among those who live far from the frontier; and (3) expanded size of the frontier decreases ability to wage war along all frontiers. When an empire’s asabiya decreases too much, it collapses. Another group with more compelling asabiya eventually helps establish a new empire.
A spatial model of resource-consumer dynamics
Arend Ligtenberg Guus Ten Broeke George Ak Van Voorn Jaap Molenaar | Published Wednesday, January 11, 2017 | Last modified Thursday, September 17, 2020The model simulates agents in a spatial environment competing for a common resource that grows on patches. The resource is converted to energy, which is needed for performing actions and for surviving.
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Peer reviewed COMOKIT
Patrick Taillandier Alexis Drogoul Benoit Gaudou Kevin Chapuis Nghi Huyng Quang Doanh Nguyen Ngoc Arthur Brugière Pierre Larmande Marc Choisy Damien Philippon | Published Tuesday, May 26, 2020 | Last modified Wednesday, July 01, 2020In the face of the COVID-19 pandemic, public health authorities around the world have experimented, in a short period of time, with various combinations of interventions at different scales. However, as the pandemic continues to progress, there is a growing need for tools and methodologies to quickly analyze the impact of these interventions and answer concrete questions regarding their effectiveness, range and temporality.
COMOKIT, the COVID-19 modeling kit, is such a tool. It is a computer model that allows intervention strategies to be explored in silico before their possible implementation phase. It can take into account important dimensions of policy actions, such as the heterogeneity of individual responses or the spatial aspect of containment strategies.
In COMOKIT, built using the agent-based modeling and simulation platform GAMA, the profiles, activities and interactions of people, person-to-person and environmental transmissions, individual clinical statuses, public health policies and interventions are explicitly represented and they all serve as a basis for describing the dynamics of the epidemic in a detailed and realistic representation of space.
…
An Agent-Based Model of Indirect Minority Influence on Social Change
Jiin Jung | Published Wednesday, February 05, 2025This model demonstrates how different psychological mechanisms and network structures generate various patterns of cultural dynamics including cultural diversity, polarization, and majority dominance, as explored by Jung, Bramson, Crano, Page, and Miller (2021). It focuses particularly on the psychological mechanisms of indirect minority influence, a concept introduced by Serge Moscovici (1976, 1980)’s genetic model of social influence, and validates how such influence can lead to social change.
Comparing agent-based models on experimental data of irrigation games
Marco Janssen Jacopo A. Baggio | Published Tuesday, July 02, 2013 | Last modified Wednesday, July 03, 2013Comparing 7 alternative models of human behavior and assess their performance on a high resolution dataset based on individual behavior performance in laboratory experiments.
Displaying 10 of 1195 results for "Aad Kessler" clear search