Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1209 results for "Ian M Hamilton" clear search
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
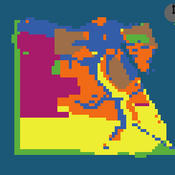
Peer reviewed ELTAP-Egy model (Energy Landscape Transition Analysis and Planning in Egypt)
Mostafa Shaaban Jürgen Scheffran Jürgen Böhner Mohamed Salah Elsobki | Published Saturday, December 29, 2018The model investigates conditions, scenarios and strategies for future planning of energy in Egypt, with an emphasis on alternative energy pathways and a sustainable electricity supply mix as part of an energy roadmap till the year 2100. It combines the multi-criteria decision analysis (MCDA) with agent-based modeling (ABM) and Geographic Information Systems (GIS) visualization to integrate the interactions of the decisions of multi-agents, the multi-criteria evaluation of sustainability, the time factor and the site factors to assess the transformation of energy landscapes.
Risks and Hedonics in Empirical Agent-based land market (RHEA) model
Tatiana Filatova Koen de Koning | Published Monday, April 01, 2019RHEA aims to provide a methodological platform to simulate the aggregated impact of households’ residential location choice and dynamic risk perceptions in response to flooding on urban land markets. It integrates adaptive behaviour into the spatial landscape using behavioural theories and empirical data sources. The platform can be used to assess: how changes in households’ preferences or risk perceptions capitalize in property values, how price dynamics in the housing market affect spatial demographics in hazard-prone urban areas, how structural non-marginal shifts in land markets emerge from the bottom up, and how economic land use systems react to climate change. RHEA allows direct modelling of interactions of many heterogeneous agents in a land market over a heterogeneous spatial landscape. As other ABMs of markets it helps to understand how aggregated patterns and economic indices result from many individual interactions of economic agents.
The model could be used by scientists to explore the impact of climate change and increased flood risk on urban resilience, and the effect of various behavioural assumptions on the choices that people make in response to flood risk. It can be used by policy-makers to explore the aggregated impact of climate adaptation policies aimed at minimizing flood damages and the social costs of flood risk.
An Agent-based Model of Firm Size Distribution and Collaborative Innovation
Inyoung Hwang | Published Monday, December 09, 2019I added a discounting rate to the equation for expected values of defective / collaborative strategies.
The discounting rate was set to 0.956, the annual average from 1980 to 2015, using the Consumer Price Index (CPI) of Statistics Korea.
Agent-based model of repeated conservation auctions in low-income countries
Sebastian Rasch Elsa Cardona Hugo Storm | Published Sunday, March 22, 2020Our model allows simulating repeated conservation auctions in low-income countries. It is designed to assess policy-making by exploring the extent to which non-targeted repeated auctions can provide biodiversity conservation cost-effectively, while alleviating poverty. Targeting landholders in order to integrate both goals is claimed to be overambitious and underachieving because of the trade-offs they imply. The simulations offer insight on the possible outcomes that can derive from implementing conservation auctions in low-income countries, where landholders are likely to be risk averse and to face uncertainty.
An agent-based model of building occupant behavior during load shedding
Handi Chandra Putra | Published Thursday, May 21, 2020Load shedding enjoys increasing popularity as a way to reduce power consumption in buildings during hours of peak demand on the electricity grid. This practice has well known cost saving and reliability benefits for the grid, and the contracts utilities sign with their “interruptible” customers often pass on substantial electricity cost savings to participants. Less well-studied are the impacts of load shedding on building occupants, hence this study investigates those impacts on occupant comfort and adaptive behaviors. It documents experience in two office buildings located near Philadelphia (USA) that vary in terms of controllability and the set of adaptive actions available to occupants. An agent-based model (ABM) framework generalizes the case-study insights in a “what-if” format to support operational decision making by building managers and tenants. The framework, implemented in EnergyPlus and NetLogo, simulates occupants that have heterogeneous
thermal and lighting preferences. The simulated occupants pursue local adaptive actions such as adjusting clothing or using portable fans when central building controls are not responsive, and experience organizational constraints, including a corporate dress code and miscommunication with building managers. The model predicts occupant decisions to act fairly well but has limited ability to predict which specific adaptive actions occupants will select.
Indirect Reciprocity with Contagious Reputation in Large-Scale Small-World Networks
Markus Neumann | Published Sunday, July 26, 2020This repository contains the replication materials for the JASSS submission: ‘Indirect Reciprocity with Contagious Reputation in Large-Scale Small-World Networks’. Further detail on how to run the models is provided in README.txt.

HyperMu’NmGA - Effect of Hypermutation Cycles in a NetLogo Minimal Genetic Algorithm
Cosimo Leuci | Published Tuesday, October 27, 2020 | Last modified Sunday, July 31, 2022A minimal genetic algorithm was previously developed in order to solve an elementary arithmetic problem. It has been modified to explore the effect of a mutator gene and the consequent entrance into a hypermutation state. The phenomenon seems relevant in some types of tumorigenesis and in a more general way, in cells and tissues submitted to chronic sublethal environmental or genomic stress.
For a long time, some scholars suppose that organisms speed up their own evolution by varying mutation rate, but evolutionary biologists are not convinced that evolution can select a mechanism promoting more (often harmful) mutations looking forward to an environmental challenge.
The model aims to shed light on these controversial points of view and it provides also the features required to check the role of sex and genetic recombination in the mutator genes diffusion.
ACTING (Affect Control Theory based simulation of Interaction in Networked Groups)
nikozoe | Published Thursday, August 19, 2021This agent-based simulation model for group interaction is rooted in social psychological theory. The
model integrates affect control theory with networked interaction structures and sequential behavior protocols as they are often encountered in task groups. By expressing status hierarchy through network structure we build a bridge between expectation states theory and affect control theory, and are able to reproduce central results from the expectation states research program in sociological social psychology. Furthermore, we demonstrate how the model can be applied to analyze specialized task groups or sub-cultural domains by combining it with empirical data sources. As an example, we simulate groups of open-source software developers and analyze how cultural expectations influence the occupancy of high status positions in these groups.
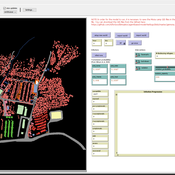
AIforGoodSimulator - Modeling Covid-19 Spread and Potential Interventions in Refugee Camps
Shyaam Ramkumar Woi Sok Oh | Published Thursday, March 18, 2021The Netlogo model is a conceptualization of the Moria refugee camp, capturing the household demographics of refugees in the camp, a theoretical friendship network based on values, and an abstraction of their daily activities. The model then simulates how Covid-19 could spread through the camp if one refugee is exposed to the virus, utilizing transmission probabilities and the stages of disease progression of Covid-19 from susceptible to exposed to asymptomatic / symptomatic to mild / severe to recovered from literature. The model also incorporates various interventions - PPE, lockdown, isolation of symptomatic refugees - to analyze how they could mitigate the spread of the virus through the camp.
Displaying 10 of 1209 results for "Ian M Hamilton" clear search