Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1209 results for "Ian M Hamilton" clear search
An agent-based simulation model simulating the problem solving process of tournament-based crowdsourcing
wiseyanjie | Published Friday, May 04, 2018 | Last modified Friday, July 06, 2018A series of studies show the applicability of the NK model in the crowdsourcing research, but it also exposes a problem that the application of the NK model is not tightly integrated with crowdsourcing process, which leads to lack of a basic crowdsourcing simulation model. Accordingly, by introducing interaction relationship among task decisions to define three tasks of different structure: local task, small-world task and random task, and introducing bounded rationality and its two dimensions are taken into account: bounded rationality level that used to distinguish industry types and bounded rationality bias that used to differentiate professional users and ordinary users, an agent-based model that simulates the problem-solving process of tournament-based crowdsourcing is constructed by combining the NK fitness landscapes and the crowdsourcing framework of “Task-Crowd-Process-Evaluation”.
The Regional Security Game: An Agent-based, Evolutionary Model of Strategic Evolution and Stability
Anthony Skews | Published Saturday, June 09, 2018The Regional Security Game is a iterated public goods game with punishement based on based on life sciences work by Boyd et al. (2003 ) and Hintze & Adami (2015 ), with modifications appropriate for an international relations setting. The game models a closed regional system in which states compete over the distribution of common security benefits. Drawing on recent work applying cultural evolutionary paradigms in the social sciences, states learn through imitation of successful strategies rather than making instrumentally rational choices. The model includes the option to fit empirical data to the model, with two case studies included: Europe in 1933 on the verge of war and south-east Asia in 2013.
An agent-based simulation model simulating the problem solving process of tournament-based crowdsourcing
wiseyanjie | Published Friday, July 06, 2018A series of studies show the applicability of the NK model in the crowdsourcing research, but it also exposes a problem that the application of the NK model is not tightly integrated with crowdsourcing process, which leads to lack of a basic crowdsourcing simulation model. Accordingly, by introducing interaction relationship among task decisions to define three tasks of different structure: local task, small-world task and random task, and introducing bounded rationality and its two dimensions are taken into account: bounded rationality level that used to distinguish industry types and bounded rationality bias that used to differentiate professional users and ordinary users, an agent-based model that simulates the problem-solving process of tournament-based crowdsourcing is constructed by combining the NK fitness landscapes and the crowdsourcing framework of “Task-Crowd-Process-Evaluation”.
The impact of potential crowd behaviours on emergency evacuation: an evolutionary game theoretic approach
Azhar Mohd Ibrahim | Published Monday, July 30, 2018Crowd dynamics have important applications in evacuation management systems relevant to organizing safer large scale gatherings. For crowd safety, it is very important to study the evolution of potential crowd behaviours by simulating the crowd evacuation process. Planning crowd control tasks by studying the impact of crowd behaviour evolution towards evacuation could mitigate the possibility of crowd disasters. During a typical emergency evacuation scenario, conflict among agents occurs when agents intend to move to the same location as a result of the interaction with their nearest neighbours. The effect of the agent response towards their neighbourhood is vital in order to understand the effect of variation of crowd behaviour on the whole environment. In this work, we model crowd motion subject to exit congestion under uncertainty conditions in a continuous space via computer simulations. We model best-response, risk-seeking, risk-averse and risk-neutral behaviours of agents via certain game theoretic notions. We perform computer simulations with heterogeneous populations in order to study the effect of the evolution of agent behaviours towards egress flow under threat conditions. Our simulation results show the relation between the local crowd pressure and the number of injured agents. We observe that when the proportion of agents in a population of risk-seeking agents is increased, the average crowd pressure, average local density and the number of injured agents increases. Besides that, based on our simulation results, we can infer that crowd disasters could be prevented if the agent population consists entirely of risk-averse and risk-neutral agents despite circumstances that lead to threats.
Human-in-the-loop Experiment of the Strategic Coalition Formation using the glove game
Andrew Collins | Published Monday, November 23, 2020 | Last modified Wednesday, June 22, 2022The purpose of the model is to collect information on human decision-making in the context of coalition formation games. The model uses a human-in-the-loop approach, and a single human is involved in each trial. All other agents are controlled by the ABMSCORE algorithm (Vernon-Bido and Collins 2020), which is an extension of the algorithm created by Collins and Frydenlund (2018). The glove game, a standard cooperative game, is used as the model scenario.
The intent of the game is to collection information on the human players behavior and how that compares to the computerized agents behavior. The final coalition structure of the game is compared to an ideal output (the core of the games).
ABMIND: An Empirically Informed Agent-Based Model of Psychological Distance and Environmental Protection Behavior
Wenhan Feng | Published Saturday, June 13, 2026ABMIND, the Agent-Based Model of Individual Psychological Distance, is a modeling framework developed to examine how psychological distance influences environmental protection behavior in coastal farming communities in southern China. Using household survey data and empirically estimated behavioral pathways, the model represents how uncertainty shapes four dimensions of psychological distance, namely temporal, spatial, social and hypothetical distance, and how these dimensions guide protection and degradation decisions. Agents include households, government actors and mangrove ecosystem patches, connected through social networks and ecological feedbacks that affect learning, expectations and perceived benefits. Policy interventions such as rewards, penalties and publicity guidance efforts work by modifying uncertainty and psychological distance rather than directly controlling behavior. ABMIND is implemented as a spatially explicit model following the ODD protocol, and a concise user guide is provided. In developing ABMIND we introduce a structured validation workflow that links statistical mediation analysis with simulation-based diagnostics, allowing empirical cognitive mechanisms to be systematically embedded and tested within the ABM. This integrated approach strengthens the credibility of psychological-mechanism models and supports their use in policy evaluation. The framework offers a methodological platform for integrating cognitive mechanisms into agent-based environmental behavior modeling and for evaluating policy strategies that support ecosystem protection.
Model paper:
ABMIND: An empirically informed agent-based model of psychological distance and environmental protection behaviour
Ecological Modelling
https://doi.org/10.1016/j.ecolmodel.2026.111700
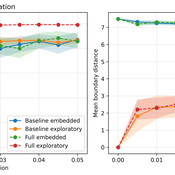
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…
A replication and extension of the Taylor's Simulation Model of Insurance Market Dynamics in C#
Rei England | Published Sunday, September 24, 2023A simple model is constructed using C# in order to to capture key features of market dynamics, while also producing reasonable results for the individual insurers. A replication of Taylor’s model is also constructed in order to compare results with the new premium setting mechanism. To enable the comparison of the two premium mechanisms, the rest of the model set-up is maintained as in the Taylor model. As in the Taylor example, homogeneous customers represented as a total market exposure which is allocated amongst the insurers.
In each time period, the model undergoes the following steps:
1. Insurers set competitive premiums per exposure unit
2. Losses are generated based on each insurer’s share of the market exposure
3. Accounting results are calculated for each insurer
…
Exploring Pesticide use and Inter-row management in European Vineyards and their potential Impacts (EPIEVI)
Nina Schwarz Yang Chen | Published Tuesday, January 24, 2023The purpose of this study is to explore the potential impacts of pesticide use and inter-row management of European winegrowers in response to policy designs and climate change. Pesticides considered in this study include insecticides, pheromone dispensers (as an alternative to insecticides), fungicides (both the synthetic type and copper-sulphur based). Inter-row management concerns the arrangement of vegetation in the inter-rows and the type of vegetation.
Peer reviewed Street Dog Sim - An agent based model for investigating strategies of free roaming dog control.
Andrew Calinger-yoak | Published Wednesday, July 19, 2023This is an agent-based model constructed in Netlogo v6.2.2 which seeks to provide a simple but flexible tool for researchers and dog-population managers to help inform management decisions.
It replicates the basic demographic processes including:
* reproduction
* natural death
* dispersal
…
Displaying 10 of 1209 results for "Ian M Hamilton" clear search