Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 148 results for "Simon Sharpe" clear search
Scholars have written extensively about hierarchical international order, on the one hand, and war on the other, but surprisingly little work systematically explores the connection between the two. This disconnect is all the more striking given that empirical studies have found a strong relationship between the two. We provide a generative computational network model that explains hierarchy and war as two elements of a larger recursive process: The threat of war drives the formation of hierarchy, which in turn shapes states’ incentives for war. Grounded in canonical theories of hierarchy and war, the model explains an array of known regularities about hierarchical order and conflict. Surprisingly, we also find that many traditional results of the IR literature—including institutional persistence, balancing behavior, and systemic self-regulation—emerge from the interplay between hierarchy and war.
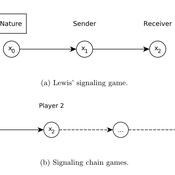
Lewis' Signaling Chains
Giorgio Gosti | Published Wednesday, January 14, 2015 | Last modified Friday, April 03, 2015Signaling chains are a special case of Lewis’ signaling games on networks. In a signaling chain, a sender tries to send a single unit of information to a receiver through a chain of players that do not share a common signaling system.
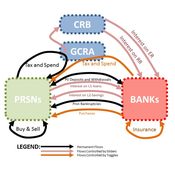
05 CmLab V1.17 – Conservation of Money Laboratory
Garvin Boyle | Published Saturday, April 15, 2017In CmLab we explore the implications of the phenomenon of Conservation of Money in a modern economy. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
Wedding Doughnut
Eric Silverman Jason Hilton Jakub Bijak Viet Cao | Published Thursday, December 20, 2012 | Last modified Friday, September 20, 2013A reimplementation of the Wedding Ring model by Francesco Billari. We investigate partnership formation in an agent-based framework, and combine this with statistical demographic projections using real empirical data.
The emergence of tag-mediated altruism in structured societies
Shade Shutters David Hales | Published Tuesday, January 20, 2015 | Last modified Thursday, March 02, 2023This abstract model explores the emergence of altruistic behavior in networked societies. The model allows users to experiment with a number of population-level parameters to better understand what conditions contribute to the emergence of altruism.
Interactions between organizations and social networks in common-pool resource governance
Phesi Project | Published Monday, October 29, 2012 | Last modified Saturday, April 27, 2013Explores how social networks affect implementation of institutional rules in a common pool resource.

Kulayinjana
Christophe Le Page Arthur Perrotton Michel De Garine-Wichatitsky Barry Bitu Killion Koyisi Ferdinand Mwamba Cephus Ncube Victor Ncube Siphusisiwe Ndlovu Raphael Ngwenya Ambu Nyathi Fumbane Nyathi Patrick Sibanda Zenzo Sibanda | Published Monday, October 03, 2016a computer-based role-playing game simulating the interactions between farming activities, livestock herding and wildlife in a virtual landscape reproducing local socioecological dynamics at the periphery of Hwange National Park (Zimbabwe).
Institutional change
Abigail Sullivan | Published Friday, October 07, 2016 | Last modified Sunday, December 02, 2018This model builds on another model in this library (“diffusion of culture”).
An Agent-Based Model to Assess Possible Interventions for Large Shigellosis Outbreaks
Erez Hatna Jeewoen Shin Sharon Greene | Published Wednesday, June 12, 2024Large outbreaks of Shigella sonnei among children in Haredi Jewish (ultra-Orthodox) communities in Brooklyn, New York have occurred every 3–5 years since at least the mid-1980s. These outbreaks are partially attributable to large numbers of young children in these communities, with transmission highest in child care and school settings, and secondary transmission within households. As these outbreaks have been prolonged and difficult to control, we developed an agent-based model of shigellosis transmission among children in these communities to support New York City Department of Health and Mental Hygiene staff. Simulated children were assigned an initial susceptible, infectious, or recovered (immune) status and interacted and moved between their home, child care program or school, and a community site. We calibrated the model according to observed case counts as reported to the Health Department. Our goal was to better understand the efficacy of existing interventions and whether limited outreach resources could be focused more effectively.
STECCAR: a simulation of the diffusion of electric cars
A Kangur Lc Verbrugge W Jager M Bockarjova | Published Sunday, November 29, 2015In this Repast model the ‘Consumat’ cognitive framework is applied to an ABM of the Dutch car market. Different policy scenarios can be selected or created to examine their effect on the diffusion of EVs.
Displaying 10 of 148 results for "Simon Sharpe" clear search