Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1010 results for "Rolf Anker Ims" clear search
Individual time preferences and adoption of destructive extraction methods
Marco Janssen Aneeque Javaid Hauke Reuter Achim Schlueter | Published Tuesday, December 06, 2016We model the relationship between natural resource user´s individual time preferences and their use of destructive extraction method in the context of small-scale fisheries.
Active Shooter: An Agent-Based Model of Unarmed Resistance
William Kennedy Tom Briggs | Published Thursday, December 29, 2016 | Last modified Tuesday, April 04, 2017A NetLogo ABM developed to explore unarmed resistance to an active shooter. The landscape is a generalized open outdoor area. Parameters enable the user to set shooter armament and control for assumptions with regard to shooter accuracy.

MCA-SdA (ABM of mining-community-aquifer interactions in Salar de Atacama, Chile)
Wenjuan Liu | Published Tuesday, December 01, 2020 | Last modified Thursday, November 04, 2021This model represnts an unique human-aquifer interactions model for the Li-extraction in Salar de Atacama, Chile. It describes the local actors’ experience of mining-induced changes in the socio-ecological system, especially on groundwater changes and social stressors. Social interactions are designed specifically according to a long-term local fieldwork by Babidge et al. (2019, 2020). The groundwater system builds on the FlowLogo model by Castilla-Rho et al. (2015), which was then parameterized and calibrated with local hydrogeological inputs in Salar de Atacama, Chile. The social system of the ABM is defined and customozied based on empirical studies to reflect three major stressors: drought stress, population stress, and mining stress. The model reports evolution of groundwater changes and associated social stress dynamics within the modeled time frame.
COVID-19 SIR with Public Health Interventions
Kit Martin Amber Cesare Matthew Johnson | Published Tuesday, September 28, 2021This is an extension of the basic Suceptible, Infected, Recovered (SIR) model. This model explores the spread of disease in two spaces, one a treatment, and one a control. Through the modeling options, one can explore how changing assumptions about the number of susceptible people, starting number of infected people, the disease’s infection probability, and average duration impacts the outcome. In addition, this version allows users to explore how public health interventions like social distancing, masking, and isolation can affect the number of people infected. The model shows that the interactions of agents, and the interventions can drastically affect the results of the model.
We used the model in our course about COVID-19: https://www.csats.psu.edu/science-of-covid19
Scholars have written extensively about hierarchical international order, on the one hand, and war on the other, but surprisingly little work systematically explores the connection between the two. This disconnect is all the more striking given that empirical studies have found a strong relationship between the two. We provide a generative computational network model that explains hierarchy and war as two elements of a larger recursive process: The threat of war drives the formation of hierarchy, which in turn shapes states’ incentives for war. Grounded in canonical theories of hierarchy and war, the model explains an array of known regularities about hierarchical order and conflict. Surprisingly, we also find that many traditional results of the IR literature—including institutional persistence, balancing behavior, and systemic self-regulation—emerge from the interplay between hierarchy and war.
Cultural transmission in structured populations
Luke Premo | Published Wednesday, November 13, 2024This structured population model is built to address how migration (or intergroup cultural transmission), copying error, and time-averaging affect regional variation in a single selectively neutral discrete cultural trait under different mechanisms of cultural transmission. The model allows one to quantify cultural differentiation between groups within a structured population (at equilibrium) as well as between regional assemblages of time-averaged archaeological material at two different temporal scales (1,000 and 10,000 ticks). The archaeological assemblages begin to accumulate only after a “burn-in” period of 10,000 ticks. The model includes two different representations of copying error: the infinite variants model of copying error and the finite model of copying error. The model also allows the user to set the variant ceiling value for the trait in the case of the finite model of copying error.
The influence of cognitive diversity on networked search and coordination
César García-Díaz | Published Wednesday, April 03, 2024Agent-based models of organizational search have long investigated how exploitative and exploratory behaviors shape and affect performance on complex landscapes. To explore this further, we build a series of models where agents have different levels of expertise and cognitive capabilities, so they must rely on each other’s knowledge to navigate the landscape. Model A investigates performance results for efficient and inefficient networks. Building on Model B, it adds individual-level cognitive diversity and interaction based on knowledge similarity. Model C then explores the performance implications of coordination spaces. Results show that totally connected networks outperform both hierarchical and clustered network structures when there are clear signals to detect neighbor performance. However, this pattern is reversed when agents must rely on experiential search and follow a path-dependent exploration pattern.
A language economics perspective on language spread: Simulating Language Dynamics in a Social Network
Marco Civico | Published Saturday, June 07, 2025This model examines language dynamics within a social network using simulation techniques to represent the interplay of language adoption, social influence, economic incentives, and language policies. The agent-based model (ABM) focuses on interactions between agents endowed with specific linguistic attributes, who engage in communication based on predefined rules. A key feature of our model is the incorporation of network analysis, structuring agent relationships as a dynamic network and leveraging network metrics to capture the evolving inter-agent connections over time. This integrative approach provides nuanced insights into emergent behaviors and system dynamics, offering an analytical framework that extends beyond traditional modeling approaches. By combining agent-based modeling with network analysis, the model sheds light on the underlying mechanisms governing complex language systems and can be effectively paired with sociolinguistic observational data.
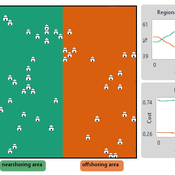
NOMAD: Near–Off Mobility under Aspiration Dynamics
Alejandro Platas López | Published Wednesday, December 17, 2025NOMAD is an agent-based model of firm location choice between two aggregate regions (“near” and “off”) under logistics uncertainty. Firms occupy sites characterised by attractiveness and logistics risk, earn a risk-adjusted payoff that depends on regional costs (wages plus congestion) and an individual risk-tolerance trait, and update location choices using aspiration-based satisficing rules with switching frictions. Logistics risk evolves endogenously on occupied sites through a region-specific absorption mechanism (good/bad events that reduce/increase risk), while congestion feeds back into regional costs via regional shares and local crowding. Runs stop endogenously once the near-region share becomes quasi-stable after burn-in, and the model records time series and quasi-stable outcomes such as near/off composition, switching intensity, costs, average risk, and average risk tolerance.
Extended Flache and Mas (2008)
Hadi Aliahmadi | Published Wednesday, August 16, 2017 | Last modified Monday, February 26, 2018We extend the Flache-Mäs model to incorporate the location and dyadic communication regime of the agents in the opinion formation process. We make spatially proximate agents more likely to interact with each other in a pairwise communication regime.
Displaying 10 of 1010 results for "Rolf Anker Ims" clear search